问题来源
最近新做一个项目,有部分搜索比较频繁的数据,而且量级比较大,预计一两年时间很可能达到100G,项目要求不要存在数据库中,最终出来有两个方案,一个是使用Protocol Buffers存储在文件上,另外就是存在Elasticsearch中,也方便搜索,但这两个方案需要验证,到底哪个方案好,从存储速度,搜索响应,占用空间方面做对比,而我负责给出Elasticsearch的部分技术建议!
验证需求
1、数据量:初步只算52亿条
2、写数据速度:需要超过1W条每秒
遇到问题以及解决办法
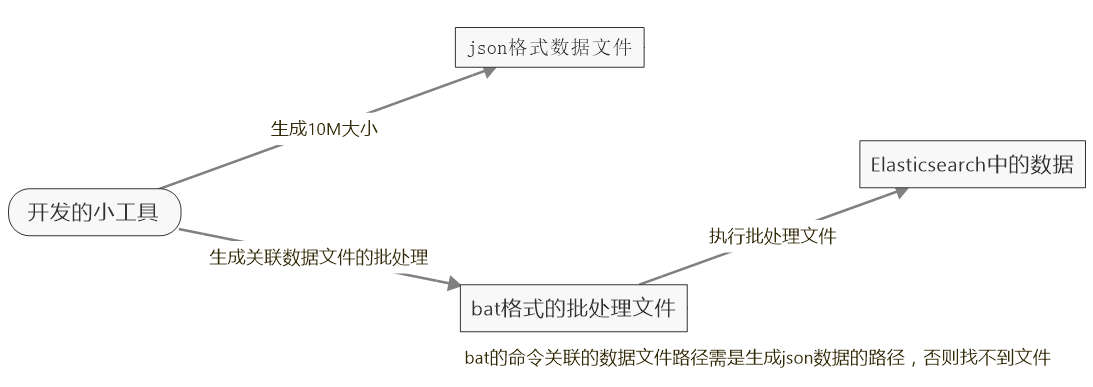
而在验证过程中遇到了无论是使用Elasticsearch.Net或者PlainElastic.Net来写数据,并且是使用了Bulk的api,加上多线程,都是太慢了,粗略算了一下,大概一秒插入3千条左右,这样的话,52亿条数据,得插到何年何月啊,太慢了,根据查阅资料,网上也有人说插入数据还是挺快 的,一秒可以插入18w条,但具体也没说是用什么办法插入的,所以只能到官方看看了,发现用REST API的_bulk来批量插入,这样速度明显快了,可以达到5到10w条每秒,速度还可以,但问题是这方法是先定义一定格式的json文件,然后再用curl命令去执行Elasticsearch的_bulk来批量插入,所以得把数据写进json文件,然后再通过批处理,执行文件插入数据,另外在生成json文件,文件不能过大,过大会报错,所以建议生成10M一个文件,然后分别去执行这些小文件就可以了,说了这么多都是文字,真的有点晕乎乎的,看图吧!
json数据文件内容的定义
| 1 2 3 4 5 6 7 8 9 10 |
|
批处理内容的定义
| 1 2 3 4 5 6 7 |
|
工具代码

1 private void button1_Click(object sender, EventArgs e)
2 {
3 //Application.StartupPath + "\\" + NextFile.Name
4 Task.Run(() => { CreateDataToFile(); });
5 }
6 public void CreateDataToFile()
7 {
8 StringBuilder sb = new StringBuilder();
9 StringBuilder sborder = new StringBuilder();
10 int flag = 1;
11 sborder.Append(@"cd E:\curl-7.50.3-win64-mingw\bin" + Environment.NewLine);
12 DateTime endDate = DateTime.Parse("2016-10-22");
13 for (int i = 1; i <= 10000; i++)//1w个点
14 {
15 DateTime startDate = DateTime.Parse("2016-10-22").AddYears(-1);
16 this.Invoke(new Action(() => { label1.Text = "生成第" + i + "个"; }));
17
18 while (startDate <= endDate)//每个点生成一年数据,每分钟一条
19 {
20 if (flag > 100000)//大于10w分割一个文件
21 {
22 string filename = new Random(GetRandomSeed()).Next(900000000) + ".json";
23
24 FileStream fs3 = new FileStream(Application.StartupPath + "\\testdata\\" + filename, FileMode.OpenOrCreate);
25 StreamWriter sw = new StreamWriter(fs3, Encoding.GetEncoding("GBK"));
26 sw.WriteLine(sb.ToString());
27 sw.Close();
28 fs3.Close();
29 sb.Clear();
30 flag = 1;
31 sborder.Append(@"curl 172.17.1.15:9200/_bulk?pretty --data-binary @E:\Bin\Debug\testdata\" + filename + Environment.NewLine);
32
33 }
34 else
35 {
36 sb.Append("{\"index\":{\"_index\":\"meterdata\",\"_type\":\"autoData\"}}" + Environment.NewLine);
37 sb.Append("{\"Mfid \":" + i + ",\"TData\":" + new Random().Next(1067500) + ",\"TMoney\":" + new Random().Next(1300) + ",\"HTime\":\"" + startDate.ToString("yyyy-MM-ddTHH:mm:ss") + "\"}" + Environment.NewLine);
38 flag++;
39 }
40 startDate = startDate.AddMinutes(1);//
41 }
42
43 }
44 sborder.Append("pause");
45 FileStream fs1 = new FileStream(Application.StartupPath + "\\testdata\\order.bat", FileMode.OpenOrCreate);
46 StreamWriter sw1 = new StreamWriter(fs1, Encoding.GetEncoding("GBK"));
47 sw1.WriteLine(sborder.ToString());
48 sw1.Close();
49 fs1.Close();
50 MessageBox.Show("生成完毕");
51
52 }
53 static int GetRandomSeed()
54 {//随机生成不重复的编号
55 byte[] bytes = new byte[4];
56 System.Security.Cryptography.RNGCryptoServiceProvider rng = new System.Security.Cryptography.RNGCryptoServiceProvider();
57 rng.GetBytes(bytes);
58 return BitConverter.ToInt32(bytes, 0);
59 }
总结
本次测试结果,发现Elasticsearch的搜索速度是挺快的,生成过程中,在17亿数据时查了一下,根据Mid和时间在几个月范围的数据,查十条数据两秒多完成查询,而且同一查询条件查询越多,查询就越快,应该是Elasticsearch缓存了,52亿条数据,大概占用500G空间左右,还是挺大的,相比Protocol Buffers存储的数据,要大三倍左右,但搜索速度还是比较满意的。
![[框架那点事儿-快速开发季]编写自己的数据持久层(6)思考](/images/no-images.jpg)
![[前端控件开发]freemarker框架下编写自己的分页器](http://hi.csdn.net/attachment/201008/3/0_1280820084W356.gif)